今天分享一款开源的声音克隆工具,OpenVoice,尽管中文语境还是效果不太好;与11Labs相比也要差些,但是是开源里面的最强者了,功能也很强大。

项目实操地址:
https://colab.research.google.com/github/hewis123/OpenVoice/blob/main/openvoice.ipynb
项目报告地址:https://arxiv.org/pdf/2312.01479.pdf
项目code地址:https://github.com/myshell-ai/OpenVoice
一、OpenVoice的实现方法和技术细节
1、解耦语音风格控制与音色克隆:
OpenVoice将语音风格控制(如情感、口音、节奏、停顿和语调)与音色克隆分离。这种解耦允许在不依赖参考说话者风格的情况下灵活控制语音风格。
通过使用基础说话者TTS模型来控制风格参数和语言,而音色转换器则专注于将参考说话者的音色嵌入到生成的声音中。
2、基础说话者TTS模型:
这个模型可以是单说话者或多说话者模型,它允许对风格参数(如情感、口音、节奏、停顿和语调)以及语言进行控制。
输出的声音被传递给音色转换器,后者改变基础说话者的音色为参考说话者的音色。
3、音色转换器:
音色转换器包含一个编码器-解码器结构,中间有一个可逆归一化流(invertible normalizing flow)。
编码器是一个1D卷积神经网络,它接收基础说话者TTS模型输出的短时傅里叶变换频谱作为输入。
音色提取器是一个简单的2D卷积神经网络,它处理输入语音的梅尔频谱图,并输出一个特征向量,编码音色信息。
归一化流层接收编码器的输出和音色特征向量,输出一个特征表示,消除音色信息但保留所有其他风格属性。
通过反向应用归一化流层,可以将参考说话者的音色特征嵌入到特征表示中,然后解码为原始波形。
4、训练过程:
基础说话者TTS模型的训练涉及收集不同语言和口音的音频样本,并使用情绪分类标签。
音色转换器的训练目标是生成自然声音,并尽可能消除音频特征中的音色信息,同时保留其他风格属性。
5、跨语言语音克隆:
OpenVoice能够实现零样本跨语言语音克隆,即使目标语言不在训练数据集中。
这通过使用国际音标(IPA)作为音素字典来实现,它允许模型生成语言中立的表示,从而即使输入的是未见语言的语音,也能顺利处理。
6、快速推理:
OpenVoice的结构是前向的,没有自回归组件,这使得它能够实现非常快的推理速度。
二、OpenVoice在不同方面的性能和效果
1、音色克隆的准确性:
OpenVoice构建了一个测试集,其中包括来自名人、游戏角色和匿名个体的参考说话者。
无论使用哪种基础说话者和参考说话者,OpenVoice都能够准确地克隆参考说话者的音色。
这表明OpenVoice在音色克隆方面具有很高的准确性,能够生成与参考说话者音色相匹配的语音。

2、语音风格的灵活控制:
为了验证音色转换器能够保留除音色以外的所有风格和语音属性,研究者使用基础说话者模型和微软TTS(使用SSML)生成了具有多种风格(情感、口音、节奏、停顿和语调)的语音语料库。
转换到参考说话者的音色后,观察到所有风格都得到了很好的保留。在极少数情况下,情感可能会略微中性化,但可以通过调整情感嵌入向量来解决。
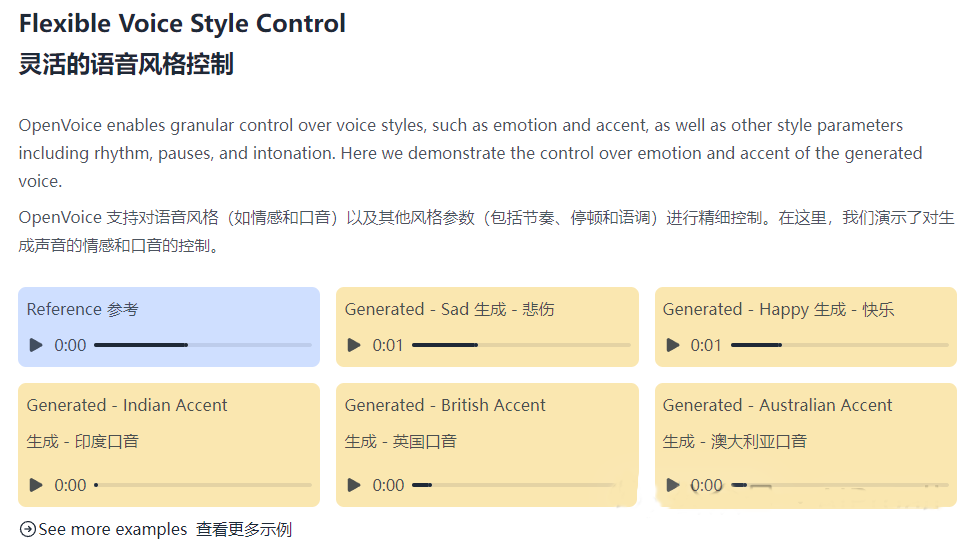
3、跨语言语音克隆的便捷性:
OpenVoice展示了其在未见语言上的克隆能力。即使参考说话者的语言或生成语音的语言不在MSML数据集中,模型也能够克隆参考说话者的音色并生成相应语言的语音。
这表明OpenVoice具有强大的跨语言适应性,即使在没有大量多说话者数据的情况下也能工作。

4、快速推理与低成本:
OpenVoice的前向结构使其具有高推理速度。实验显示,经过轻微优化的OpenVoice版本(包括基础说话者模型和音色转换器)能够在单个A10G GPU上实现12倍实时性能,即生成一秒语音只需要85毫秒。
通过详细的GPU使用分析,估计其性能上限大约为40倍实时,但将这一改进留给未来的工作。
5、国际音标(IPA)的重要性:
使用IPA作为音素字典对于音色转换器在跨语言语音克隆中的表现至关重要。
在训练过程中,文本首先被转换为IPA音素序列,然后每个音素由可学习向量表示。这些向量表示被编码并与流层的输出进行对比,以消除音色信息。
IPA作为一个跨语言统一的音素字典,使得流层能够生成语言中立的表示。即使输入的是未见语言的语音,模型也能够顺利处理。
最后
我们是信用卡开卡平台4399pay,有532959等经典卡段十余种,支持各平台投放,海淘,467413卡段支持ChatGPT。无限开卡安全可靠收费透明,期待你的关注!


