

1
背景信息
▍Stable Diffusion 是什么?
Stable Diffusion(简称SD)是一种生成式人工智能,于2022年发布,主要用于根据文本描述生成详细图像,也可用于其他任务,如图像的修补、扩展和通过文本提示指导图像到图像的转换。除图像外,您还可以使用该模型创建视频和动画。
这是AI绘画第一次能在可以在消费级显卡上运行,任何人都可以下载模型并生成自己的图像。另外,SD高质量的成图以及强大的自由度(自定义、个性化)受到诸多网友的追捧。Stable
Diffusion XL 1.0 (SDXL 1.0) 是Stable Diffusion的一个更为高级和优化的版本,它在模型规模、图像质量、语言理解和模型架构等方面都有显著的改进。
▍Stable Diffusion 能做什么?
首先,大家在入坑SD前,务必要清楚现阶段的SD到底能做什么?能否满足自己的需求?
Stable Diffusion 功能包括文本转图像、图像转图像、图形插图、图像编辑和视频创作。
-
文本转图像生成:最常见和最基础的功能。Stable Diffusion 会根据文本提示生成图像。
-
图像转图像生成使用输入图像和文本提示,您可以根据输入图像创建新图像。典型的案例是使用草图和合适的提示。
-
创作图形、插图和徽标使用一系列提示,可以创建各种风格的插图、图形和徽标。
-
图像编辑和修正可以使用 Stable Diffusion 来编辑和修正照片。例如,可以修复旧照片、移除图片中的对象、更改主体特征以及向图片添加新元素。
-
视频创作使用 GitHub 中的 Deforum 等功能,可以借助 Stable Diffusion 创作短视频片段和动画。另一种应用是为电影添加不同的风格。 还可以通过营造运动印象(例如流水)来为照片制作动画。
2
安装和部署Stable Diffusion
介绍如何安装和部署Stable Diffusion。我使用的是秋葉aaaki的整合包,文章末尾提供180G整合包~
电脑系统:Windows10及以上/macOS Monterey (12.5)。
显卡:RTX3060及以上。
显存:8G及以上。
内存:16G及以上。
磁盘空间:500 SSD及以上
▍操作步骤
步骤一:右键解压Stable Diffusion安装包。
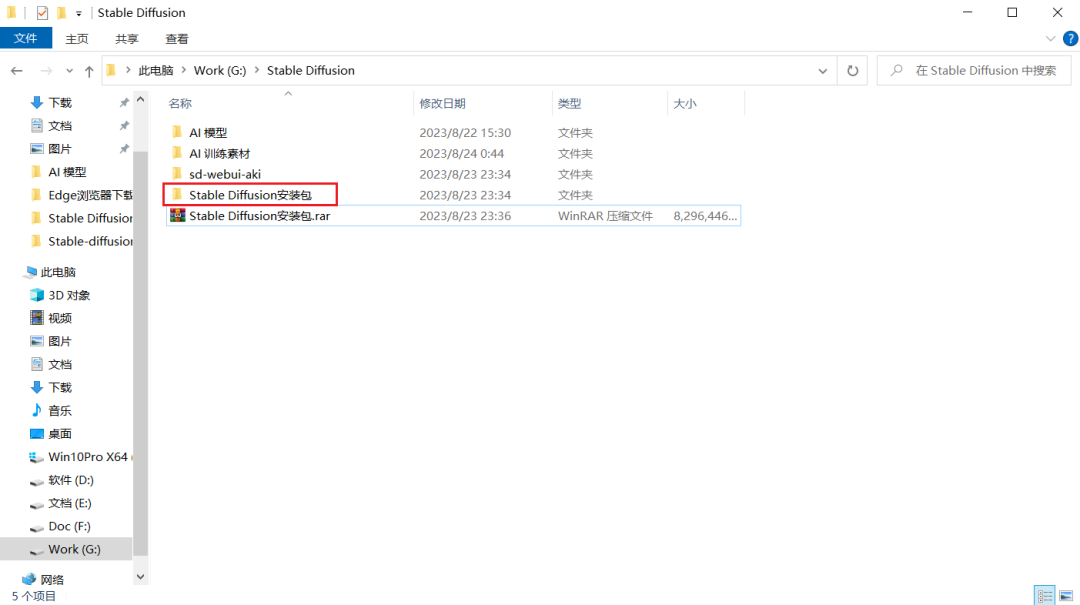
步骤二:双击Stable Diffusion安装包进入文件夹中,解压sd-webui-aki-v4.2。
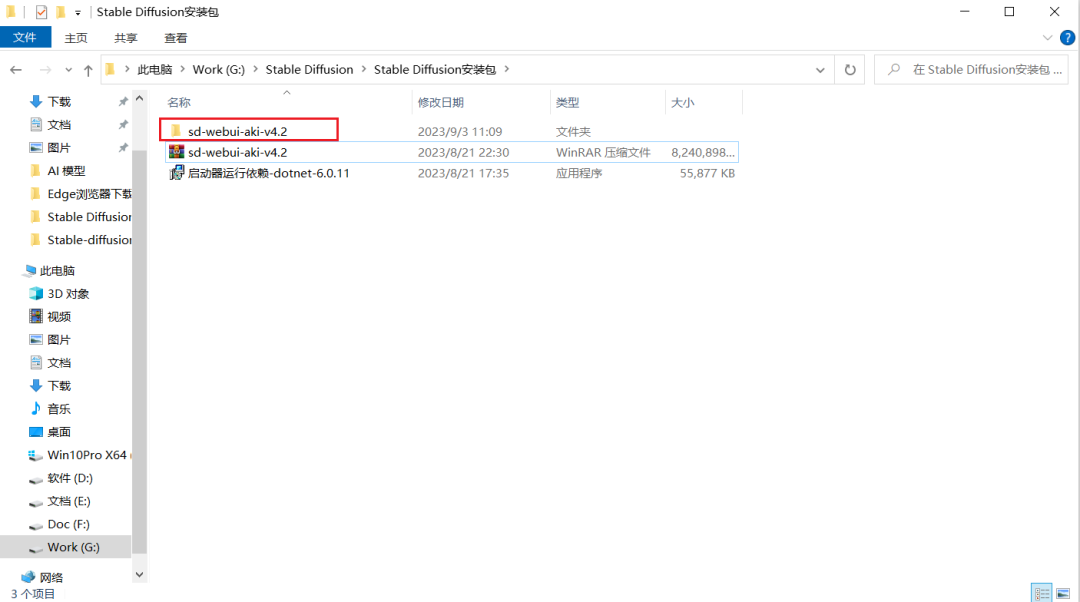
步骤三:双击启动器运行依赖-dotnet-6.0.11,安装所需依赖。
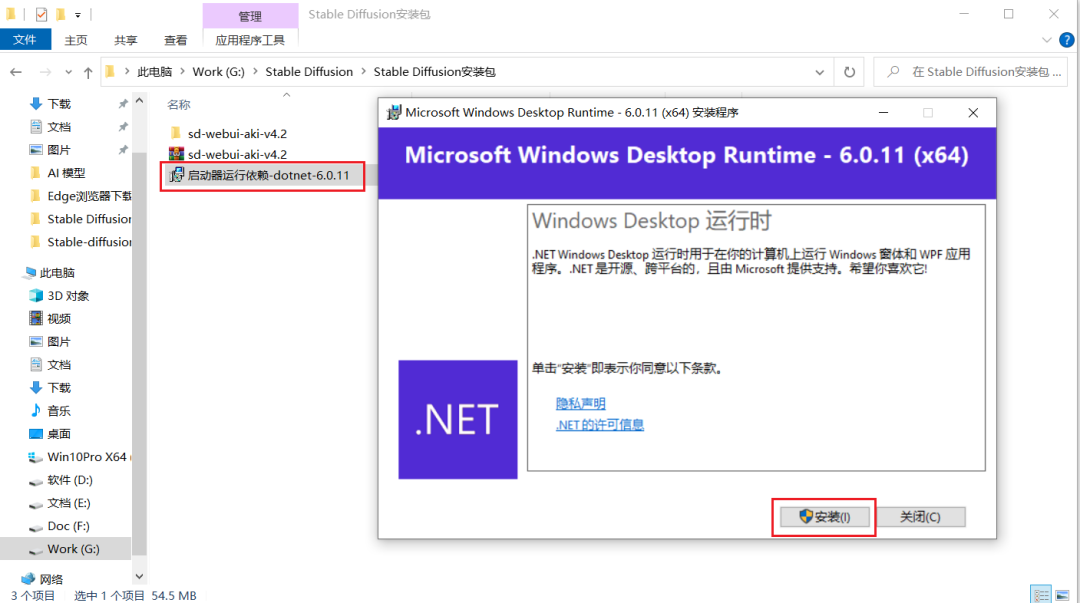
步骤四:双击sd-webui-aki-v4.xx进入该文件夹中,下拉找到A启动器并启动。
注:第一次启动,需要一些时间部署Python和Git环境,请耐心等待,后面启动就很快了。若未弹出WebUI界面,请将复制链接:http://127.0.0.1:7860 到浏览器中即可。
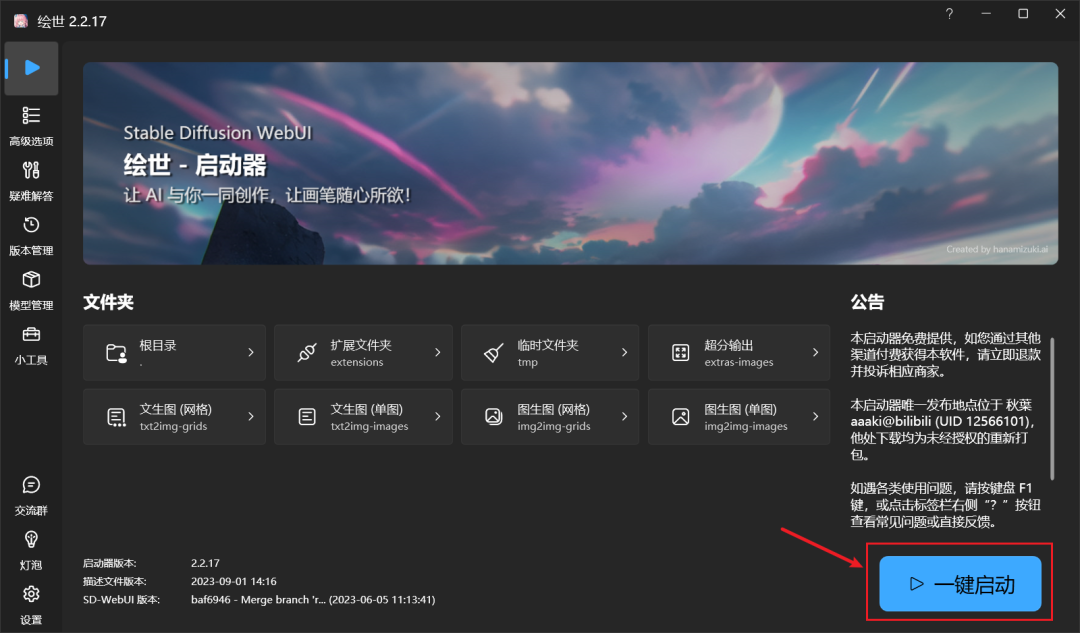
若弹出Stable Diffusion WebUI界面,则表示启动成功。
3
Stable Diffusion教程与模型

Stable Diffusion WebUI界面介绍
▍Stable Diffusion WebUI 介绍
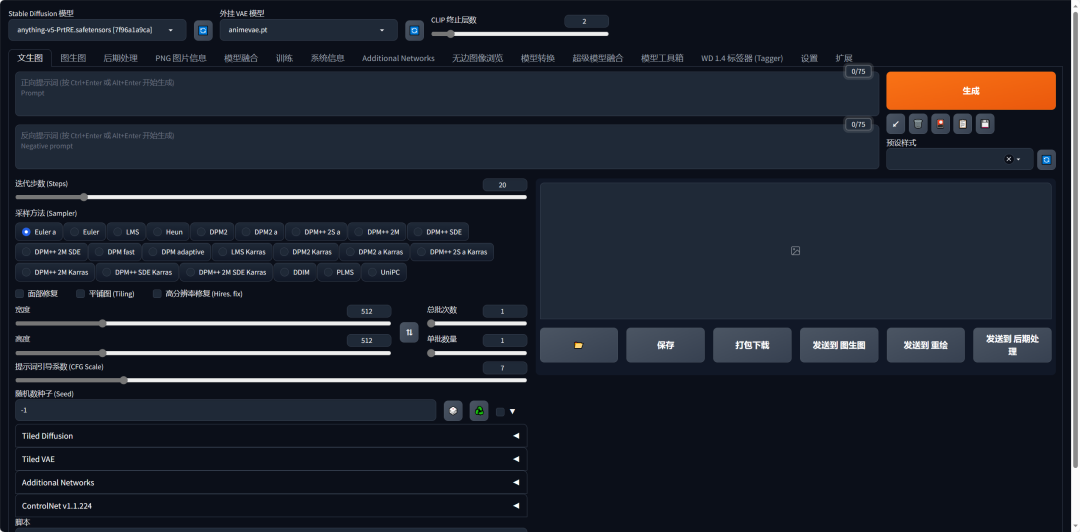
1. Stable Diffusion WebUI界面主要分为三个区域:模型选择区、功能选择区、参数配置区。
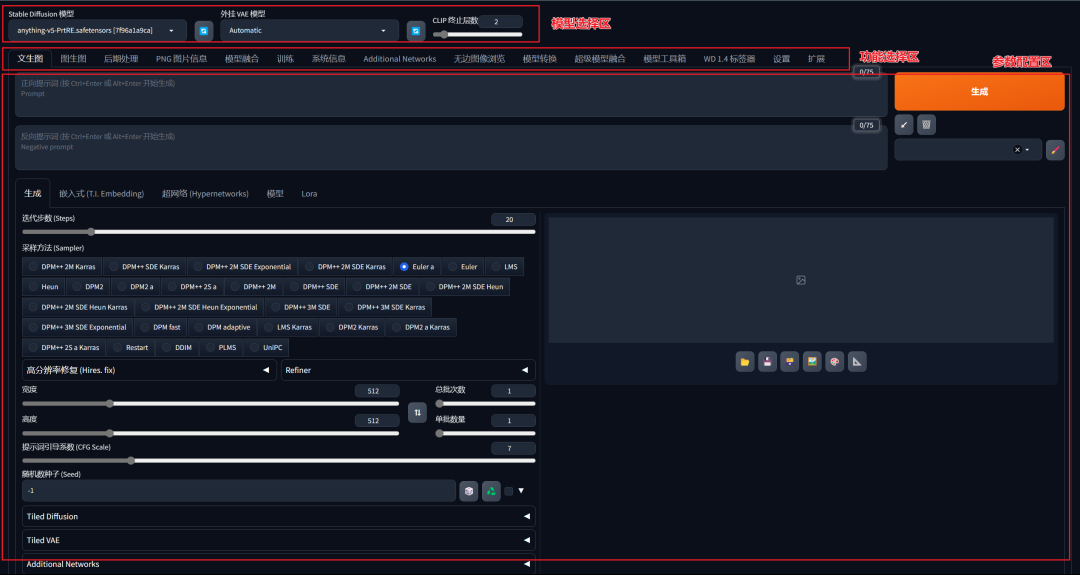
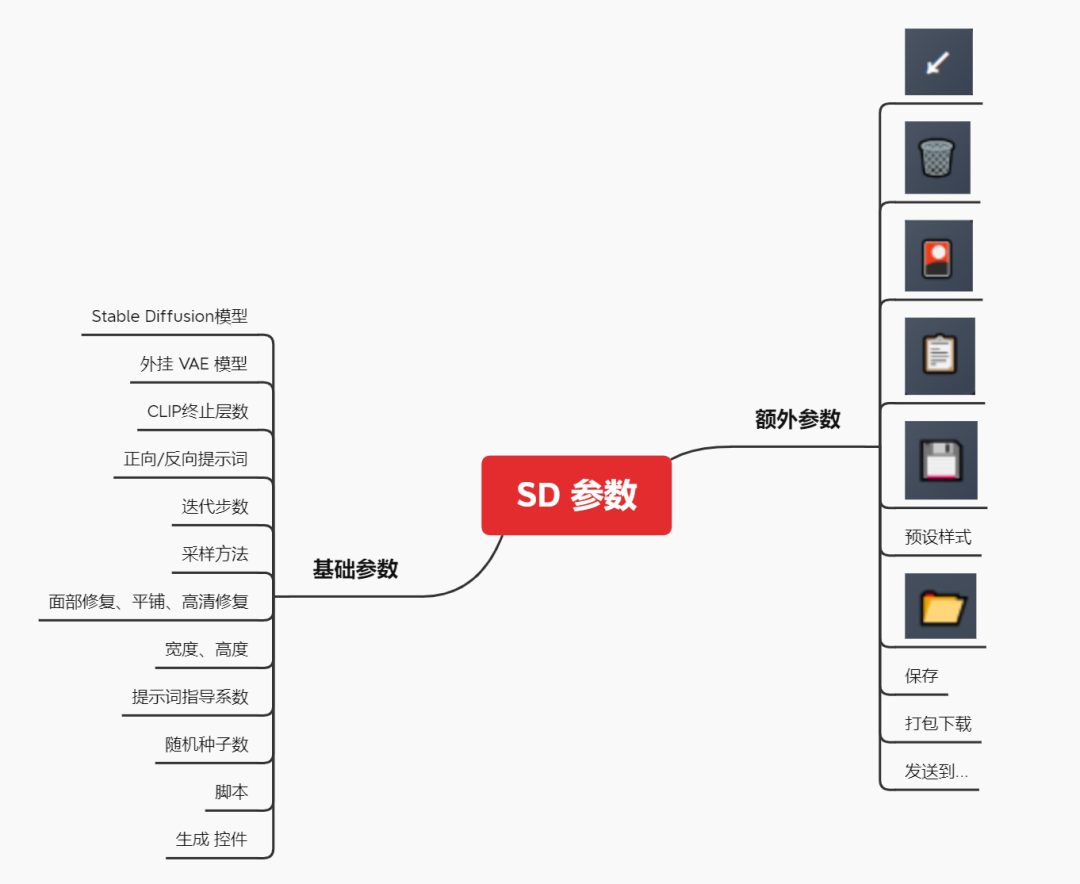
2. 里面的参数非常多,第一次看到定会眼花缭乱,我对此进行了一次归类分组,这些参数主要分为两类:
一是为了告诉AI,用户的需求是什么,进而完成作图任务,称为基础参数。如提示词框、模型选择,迭代步数,采样器,图片尺寸等。
二是为了高效率地完成这个任务而存在的参数,称为额外参数,是非必要的参数。如垃圾桶,一键清除提示词、文件夹、打包下载、预设样式等。
那么,现在我们在看到某个参数时就知道它大致的作用是什么了。
Stable Diffusion 布局/参数介绍
接下来我将依次介绍Stable Diffusion文生图功能中的参数,指导用户快速了解和使用这些参数,以便更好地出图。
注:1. 这里的参数介绍只起到指导性作用,若想进一步了解各个参数的细节和原理,请阅读后续的文章。2. 由于这是整合包相比较原生的Stable Diffusion安装包,功能较多,且已经汉化了。
模型选择区
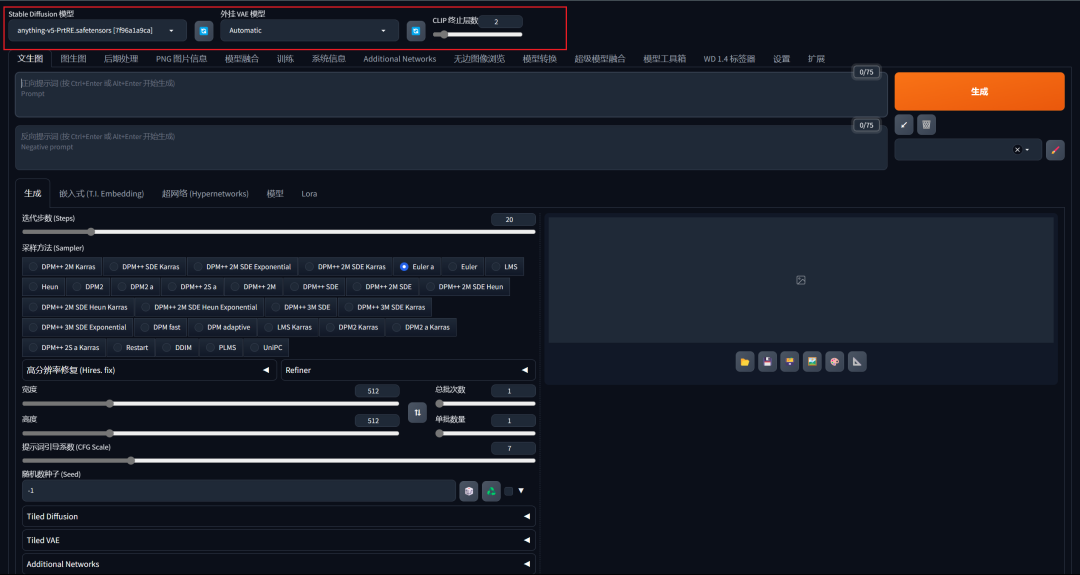
1. Stable Diffusion模型:下拉选择大模型,默认anyting-V5模型。请根据自身需求选择不同类型的模型,如现实主义风格的模型;动漫,二次元风格的模型。
2. 外挂VAE模型:下拉选择VAE模型,默认无。是可选操作,可以选择不同效果的VAE模型,对成图细节或颜色进行修复,同时选择VAE也可以起到节省电脑算力的作用。
3. CLIP终止层数(Clip Skip):滑动确认或输入层数,层数范围为1~12层,默认层数为2。1层,成图更加精确;2层,成图更加平衡,即AI遵循提示词,也有一定自己的创意;3-12层,成图更加有创意。这里推荐2层。若你希望AI更加有自己的创意,还是请调节提示词引导系数(CFG Scale)参数,效果会更好。
注:选择模型时,需要提前下载模型并存储到对应的路径中。模型下载可前往:huggingface网站或Civital网站。Stable Diffusion模型存储位置是:
*\models\Stable-diffusion。VAE模型存储位置是:*\models\VAE。存储完后,点击“?”即可。

Stable Diffusion
180G
秋葉aaaki整合包+教程

下载整合包后,点击里面的启动器,点击启动界面的一键启动,启动器会自动启动Stable Diffusion Web UI,并打开浏览器
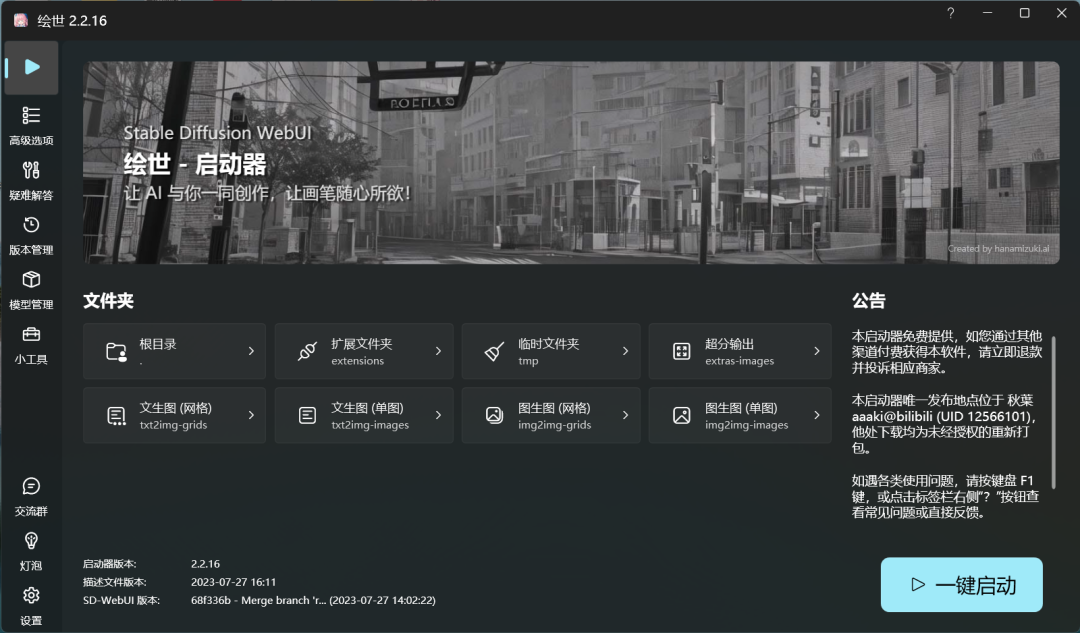
打开后的Stable Diffusion Web UI界面。
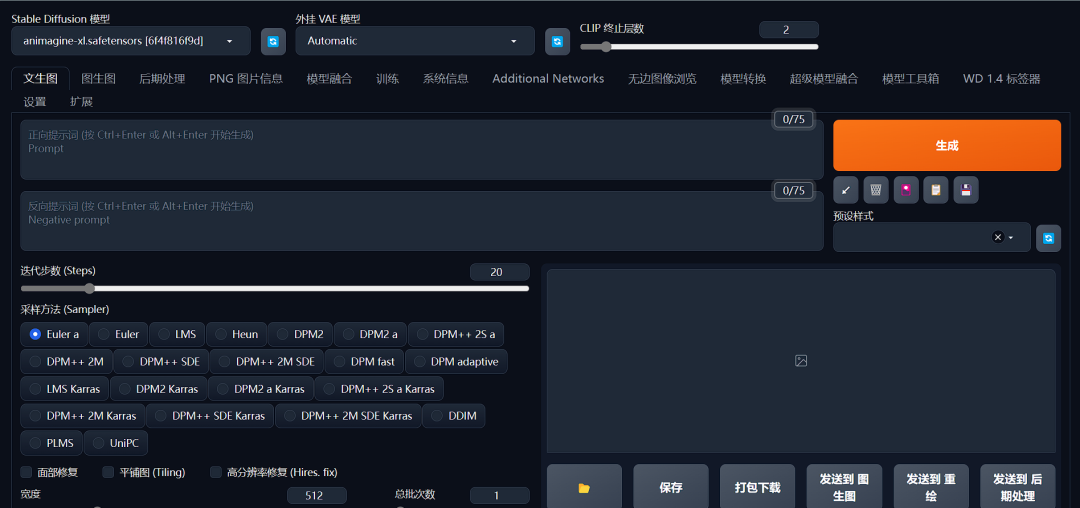
使用的时候,输入正面提示词和反面提示词(非必须),其他的选项使用默认的就行,然后点击 生成,稍微等待一会,就可以得到生成的图片了。
Stable Diffusion Web UI 界面原本是英文的,我们只需要在其启动器的高级设置中启用云端页面汉化设置,就可以完成Stable Diffusion Web UI 汉化。

是不是很喜欢?
喜欢就抱走吧!
欢迎对我们的原创文章进行讨论和私信,希望更多的小伙伴可以和我们一起进步!本号推荐的插件工具如果有什么相关问题也可以关注公众号后详细咨询,我们会在第一时间为您提供满意的服务。
点个在看支持一下,你的【赞】是小编更新的动力!
比心~

免责声明:资源均来源于网络共享资源,仅供个人学习、研究之用,请勿用作商业用途。
—The end—
!

慧眼看视界
扫码|关注我们
微信号|Plugfans
好文章和好插件一样也不能少。
来源:北京灵动像素


