
微软提出使用人手运动视频直接教机器人完成任务的新方法,这种方法使用 GPT-4V 分解视频中的动作,结合大语言模型生成对应的行为表述并作为任务列表,训练机器人只需要动动手就能完成。
如何将语言 / 视觉输入转换为机器人动作?
训练自定义模型的方法已经过时,基于最近大语言模型(LLM)和视觉语言模型(VLM)的技术进展,通过 prompt 工程使用 ChatGPT 或 GPT-4 等通用模型才是时下热门的方法。
这种方法绕过了海量数据的收集和对模型的训练过程,展示出了强大的灵活性,而且对不同机器人硬件更具适应性,并增强了系统对研究和工业应用的可重用性。
特别是最近出现了通用视觉大模型(VLM),如 GPT-4V,将这些视觉系统集成到任务规划中,为开发基于多模态人类指令的任务规划器提供了可能性。
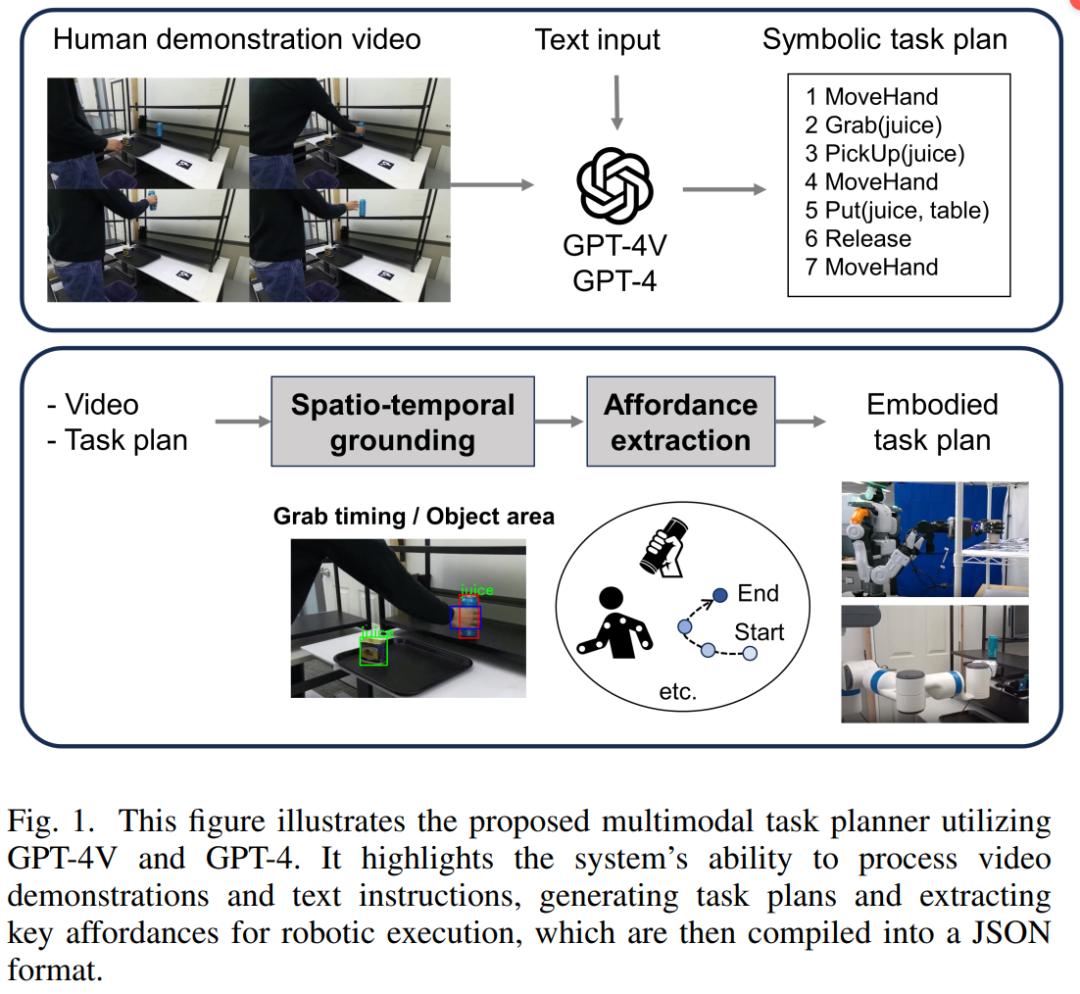
在近期微软的一篇论文中,研究者利用 GPT-4V 和 GPT-4(图 1)分别作为最新的 VLM 和 LLM 的范例,提出了一种多模态任务规划器。该系统可以接受内容为人类行为的视频和文本指令等输入,甚至可以同时接受二者,并输出符号化的任务规划(即一系列连贯的任务步骤)。

论文地址:https://arxiv.org/pdf/2311.12015.pdf
代码即将公开:https://microsoft.github.io/GPT4Vision-Robot-Manipulation-Prompts/
当视觉数据可用时,系统会根据任务规划重新分析视频,并在每个任务和视频之间建立时空上的对应关系。这一过程可以提取对机器人执行有价值的各种能力信息,如接近物体的方式、抓握类型、避免碰撞的路径点和上肢姿势等。
最后,能力(affordance)信息和任务规划被编译成独立于硬件的可执行文件,以 JSON 格式保存。本文对模型进行了定性分析,并确认了输出的任务规划在多个真实机器人上的可操作性。
技术细节
本文提出的系统由两个串联的部分组成(图 2):
第一部分是符号任务规划器,将人类行为的教学视频、文本或两者共同作为输入,然后输出一系列的机器人动作。在这里,文本输入也包括对 GPT-4V 识别结果的反馈,以便进行修正。为用户提供对识别结果进行反馈的机会,可以得到更加鲁棒的操作作为输入,换句话说,当系统任务用户操作不准确时,还能有机会重新输入。
第二部分是能力分析器,负责分析视频以确定任务发生的时间和地点,然后提取高效执行任务所需的能力信息。
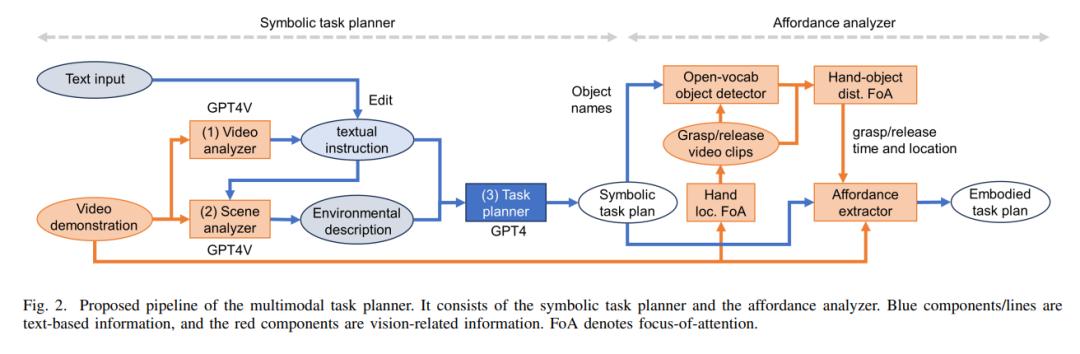
在这一系统中,输入的视频是人类执行动作的演示,让机器人去复制。本研究实验中假定视频的粒度为抓握 – 操纵 – 释放。
A. 符号任务规划器
符号任务规划器由三个部分组成:1) 视频分析;2) 场景分析;3) 任务规划。
最初,当输入 RGB 视频时,视频分析使用 GPT-4V 来识别视频中人类所做的动作,并将其转录为人与人交流中使用的文本指令(例如,请扔掉这个空罐子)。在视频分析中,考虑到模型 token 的限制和延迟,本文采用了视频帧定时采样的方法,并将抽到的帧输入 GPT-4V。然后由用户对输出文本进行检查和编辑。如果不提供视频输入,则在此阶段向系统提供文本指令。图 3 显示了视频分析器的示例,表明 GPT-4V 可以成功地从帧中理解人的动作。

接下来,场景分析器根据这些指令和工作环境的第一帧视频数据或图像,将预期的工作环境编译成文本信息。这些环境信息包括 GPT-4V 识别的物体名称列表、物体的可抓取属性以及物体之间的空间关系。虽然这些计算过程在 GPT-4V 中是一个黑盒,但这些信息是根据 GPT-4V 的知识和输入的图像 / 文本输出的。
图 4 显示了场景分析器的示例。如图所示,GPT-4V 成功地选择了与操作相关的对象。例如,当人类在桌子上移动垃圾桶时,输出中包含了桌子,而在打开冰箱的任务中则忽略了桌子。这些结果表明,场景分析器可以根据人类的操作对场景信息进行编码。

根据给定的文本指令和环境信息,任务规划器会输出一系列任务。
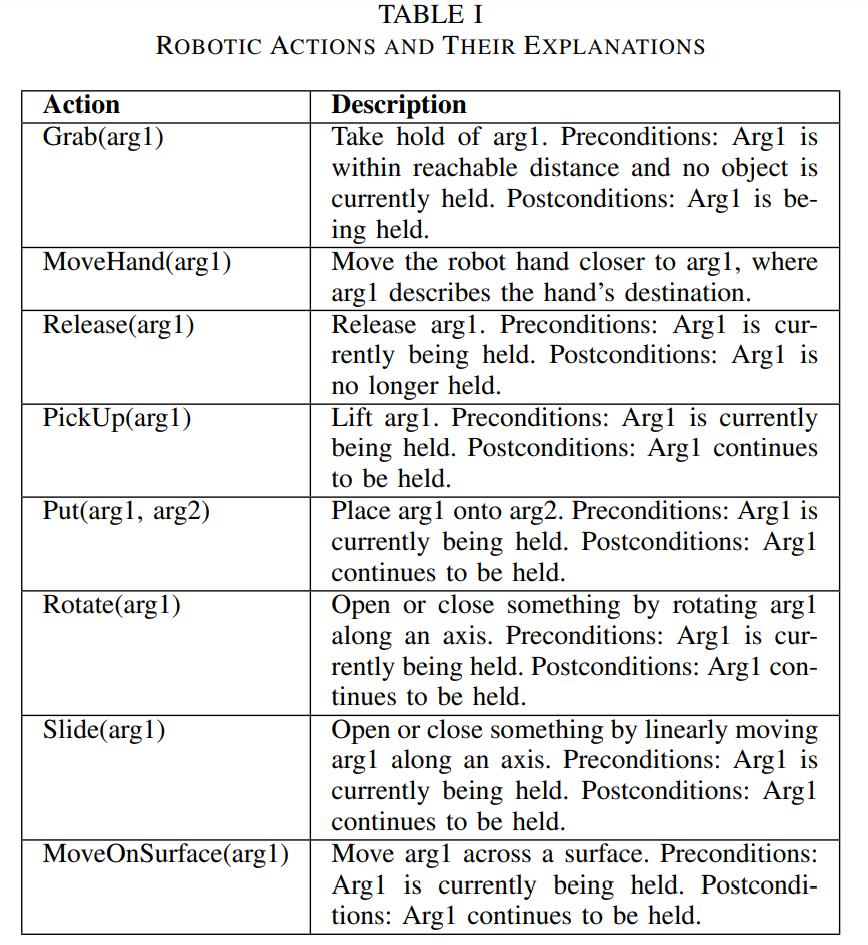
具体来说,本文设计了一个 prompt,让 GPT-4 将给定指令分解为一系列机器人任务 。本文又根据 Kuhn-Tucker 理论,建立了一套必要且充分的机器人操作物体的动作。
表 I 显示了本文在 prompt 中包含的任务集和解释。在这里,任务参数的名称是基于对 GPT-4V 的理解,以开放词汇格式给出的。在后续阶段,这些名称将通过能力分析器与视频结合起来。此外,这些前 / 后条件用于强制 GPT-4 输出连贯的任务序列,而不是根据视频中的意象进行验证。
为了确保对 GPT-4 模型理解的透明度,任务规划器被设计为输出任务解释、操作后的估计环境和操作摘要,以及一组任务规划。此外,任务规划器还是一个有状态的系统,可在 GPT-4 模型的 token 限制范围内保持过去对话的历史记录。因此,用户可以根据任务规划器的输出,通过语言反馈来修改和确认输出。图 5 显示了任务规划器的计算结果示例。结果表明,一套量身定制的 prompt 可以产生合理的文本指示、环境描述和符号任务规划。

B. Affordance 分析器
Affordance 分析器利用来自符号任务规划器的知识对给定视频进行重新分析,以获取机器人有效执行任务所需的能力信息。
具体来说,它根据任务的性质和物体名称,重点分析手与物体之间的关系。它能识别视频中抓取和释放的时刻和位置,并将这些时刻和位置与任务序列对齐。这些瞬间可作为锚点,用于识别每项任务所必需的能力。
1) 通过关注人手来检测抓取和释放的动作:起初,模型将一系列视频按固定的时间间隔分割成视频片段。然后使用手部检测器和图像分类器对每个视频片段的开始和结束帧进行分析,以确定物体是否被抓(图 6)。视频片段被分为以下几种模式:
在第一帧中没有任何东西被抓住,但在最后一帧中却有东西被抓住的片段表示发生了抓取。
在第一帧中有东西被握住,而在最后一帧中没有东西被握住的片段表示发生了释放。
其他片段则被归类为包含其他类型动作的片段。

通过这种分类,分析器可以确定哪些视频片段包含抓握和松开的实例。为此,研究者开发了基于 YOLO 的手部检测器和识别器 ,并已将该模型开源(https://github.com/ultralytics/ultralytics)。
2) 通过关注手与物体的交互,实现检测抓取和释放的时空位置。然后,模型将重点放在抓取视频片段上,分析抓取物体的位置和时间。本文使用 Detic(一种开放式词汇对象检测器)来搜索视频中的候选对象,正如符号任务规划器所识别的那样,当识别出多个候选对象时,视频片段中最靠近手部的对象将被视为抓取对象。这是通过比较手部检测器在抓取视频片段的每一帧中检测到的每个候选对象的边界框与手部之间的距离来确定的。图 7 展示了物体检测的计算过程。在「抓取」视频片段中,手与物体在空间上最接近的时刻被确定为抓取时刻。类似的计算也应用于释放视频片段,以确定释放的时间。

图 8 显示了将果汁罐从货架底部移到顶部的操作计算过程。

3) 本文将抓取和松开的瞬间看作任务序列与视频对齐的锚点,对齐后,视觉分析器会提取以下信息,包括:
抓取任务的能力:1)接近物体的方向信息,以避免与环境发生碰撞。2)抓取类型还包含人类如何有效的执行操作。
手部移动的能力:1)手移动过程中的航点信息,以避免环境碰撞。
释放任务的能力:1)释放物体后手的撤离方向信息,以避免环境碰撞。
拾取任务的能力:1)矢量化的离开方向信息,以尽量减少物体与平面之间不必要的力。
放置任务的能力:1)朝物体靠近方向的信息,以避免环境碰撞。
旋转任务的能力:1)旋转轴的方向。2) 旋转中心的位置。3)旋转角度。
滑动任务的能力:1)滑动运动的位移。
表面移动任务的能力:1)与表面垂直的轴。
除了这些能力外,上臂和前臂在抓取、释放和每个时刻的姿态也被编码为一对离散的方向向量。这些向量可作为计算多自由度手臂逆运动学的约束条件,确保机器人不会在人类周围摆出意想不到的姿势。值得注意的是,虽然这些能力为许多控制器提供了可行的信息,但机器人的实际执行可能还需要力反馈等额外信息。
实验结果
研究者将模型进行了封装,并设计了网页访问接口,如图 9 所示。
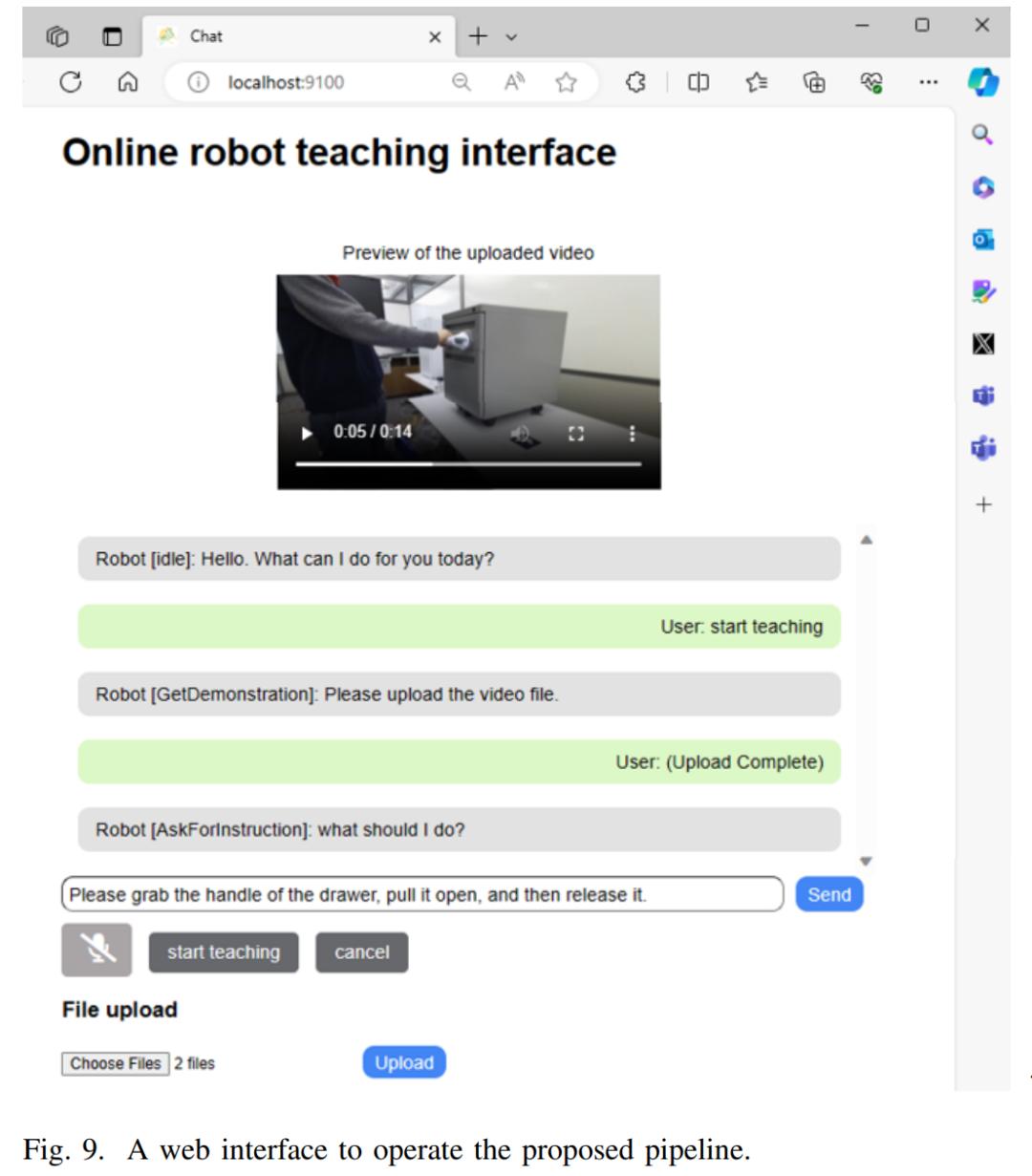
该模型允许用户上传预先录制的教学演示,并让 GPT-4V 和 GPT-4 对任务模型进行编码。然后,研究者测试了机器人能否通过在各种场景下获得的视频进行一次尝试操作。此处研究者介绍了几个执行示例。实验测试了两个机器人:第一个是 Nextage 机器人(川田机器人公司出品)其手臂有六个自由度;第二个是 Fetch 移动机械手(Fetch 机器人公司出品),其手臂有七个自由度。机器人上还装有一个四指机械手,即 Shadow Dexterous Hand Lite(Shadow Robotics)。机器人的技能是通过强化学习训练出来的。所有实验结果将可以在其官方代码库中访问(代码即将公布)。
最后
我们是信用卡开卡平台4399pay,有532959等经典卡段十余种,支持各平台投放,海淘,支持ChatGPT支付。无限开卡安全可靠收费透明。


