
对于这样一柄双刃剑,要用好只听一面之词显然不够。
作为一家在AI领域深耕多年的独角兽,OpenAI首次进入公众视野是在2022年秋季发布的ChatGPT,但这并不代表OpenAI在ChatGPT之前就毫无建树。其实在推出ChatGPT前,OpenAI做了打《DOTA2》的AI程序OpenAI Five,以及开源AI语音转文字工具Whisper。

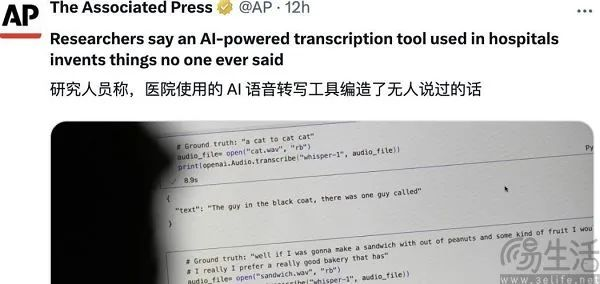
如果说OpenAI Five是小试牛刀,那么Whisper自然就是OpenAI方面当时希望用技术扬名的作品。以至于在Whisper发布四年后的今天,OpenAI还在DevDa活动日中推出了Whisper large-v3-turbo语音转录模型。只可惜这次Whisper翻车了,据相关报道显示,其通过采访工程师、开发人员和学术研究人员后发现,Whisper编造内容的问题被暴露了出来。
据悉,Whisper很容易编造大段文本、甚至整句话,这些幻觉中包含种族评论、暴力言论,乃至编造的医生与患者对话。有开发者透露,他用Whisper创建的26000份转录样本中几乎每一份都出现了幻觉。甚至有开发者分析了100多个小时的Whisper转录样本后发现,其中约有一半内容存在幻觉。

AI会因为幻觉(AI Hallucinations)而胡说八道,其实早已是公认的现实,无论国内的文心一言、Kimi、混元,还是海外的ChatGPT、Gemini,目前还都无法拍着胸脯保证AI不会答非所问、胡编乱造。而AI大模型之所以会产生幻觉,就好比人类会做梦一样,现阶段还是无可避免的规律。
尽管AI会幻觉正常,但Whisper如此频繁地出现幻觉就有些反常了,而“发病”概率过高才是相关报道被广泛关注的基础。而且不仅是随口转录会出问题,即便是录制良好的短音频,转录幻觉的问题还是很普遍,有研究人员在他们检查的13000多个清晰音频片段中,就有187个片段中出现了幻觉。
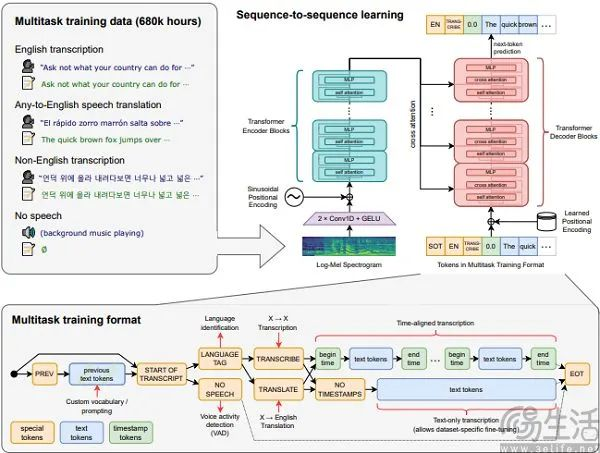
AI致幻的原因其实很简单,因为大模型就是一个本身就基于概率的黑箱产物,它的预训练机制是从训练数据中进行泛化,以便获得类似人类的推理能力。然而当模型过度调整训练数据时就会发生过度拟合,有效地记住了该集合的特定输入和输出,从而影响其有效处理样本之外数据的能力。
想要解决AI幻觉,在不改变当下大模型训练机制的情况下只有唯一一种解法,即将全世界所有的知识都填充到一个数据库里。只可惜,没有哪一家厂商敢于宣称拥有一个完全覆盖所有知识的“图书馆”。但无法避免的幻觉所导致的结果,就是AI会输出表面上看合理、且富有逻辑,但实际上却存在事实错误或压根不存在的内容。
人工智能有幻觉才是它肖似人类的关键,毕竟人非圣贤孰能无过,AI也一样。问题是各路AI厂商和媒体为了营造AI热潮,将AI的能力放大,过于夸大了AI的上限。以至于在宣传口径里,基于大模型的AI已经是《终结者》里无所不能的“天网”,进而也放大了AI幻觉的负面性。
当下一个不可忽视的情况,是相比于对AI有所警惕的群体,敢于尝鲜ChatGPT等AI产品的群体反而会成为AI幻觉的受害者。因为当AI将错误以一种有说服力和可信度的方式呈现出来后,习惯于使用AI的人反而会忽视事实验证的情况,并接收到错误的信息。“善游者溺、善骑者堕,各以所好反自为祸”,老祖宗的话并不是没有道理。
事实上,目前AI普及最大的难题,就是宣传调门太高与实际应用的局限性产生了冲突。作为一款语音转录产品,Whisper目前已经被不少海外医疗机构启用,以提升医生的工作效率,并且在后续的诊疗过程中,医疗人员大概率会以Whisper转录的内容来作为依据。这时候Whisper出现凭空编造医患对话的情况,又怎能不让海外网友感到惊恐。
尽管AI大模型、AIGC确实是好东西,可是在相关厂商的宣传里,幻觉导致的一系列问题被有意无意地忽视了。在用户的朴素认知里,AI能够掌握大数据、算力也更强,所以它得出的结论一定是更有参考的价值的,这也是目前市面上AI购物助手诞生的土壤。可一旦AI购物助手产生幻觉,消费者就得损失金钱,Whisper产生幻觉、患者就可能会被误诊。

游走在权力与责任边缘的AI,既带来了巨大的效率提升,还隐藏着无法忽视的风险。对于这样一柄双刃剑,要如何用好它如果只听“贩剑”的AI厂商一面之词显然不够。
写在最后,如果你需要付费使用ChatGPT等AI工具,可选择开通虚拟卡进行支付。4399Pay就是一家专门提供国际虚拟信用卡的平台,可以免KYC;有兴趣的朋友可以添加客服TG(@dabai717)进行了解


