近日,开发 ChatGPT 的 OpenAI 公司又放出王炸 Sora,一个可以根据文本生成视频的 AI 模型。

OpenAI 公布的 Sora 生成的视频片段无疑将视频生成技术推向了一个崭新的高度,标志着人工智能在视频创作领域迈入了新的里程碑。这一技术的出现,无疑为电影、动画、游戏、广告等多个内容创作领域带来了革命性的变化。
Sora 的出色表现,使得内容创作者们能够拥有更加便捷、高效的创作工具。它不仅能够快速生成高质量的视频片段,还能够在短时间内完成复杂的特效处理,极大地提高了内容创作的效率。

尽管 Sora 的源代码并未开源,但GitHub 上惊喜地出现了 Colossal-AI 团队开源的完整 Sora 复现架构方案——Open-Sora。这一方案提供了从数据处理到模型训练,再到部署的详尽步骤,为渴望探索 Sora 技术的开发者们打开了一扇窗。
Open-Sora 不仅成功降低了 46% 的复现成本,使得更多开发者能够接触并研究这一前沿技术,而且它还进一步提升了模型训练的效能,将输入序列长度扩充至 819K patches,这意味着模型能够处理更细致、更复杂的视频内容。
Open-Sora 的出现,无疑为视频生成技术的发展注入了新的活力,推动了该领域的研究和应用向更高层次迈进。
GitHub 地址:https://github.com/hpcaitech/Open-Sora
既然 Sora 没有开源,那这个复现方案从何而来呢?接下来,就让我们一起来看看已公布的 Sora 技术原理以及 Open-Sora 到底有没有真东西!
Sora 算法复现方案
随着 Sora 视频的发布,OpenAI 还公布了一份详尽的技术报告,深入剖析了 Sora 的工作原理。报告显示,Sora 利用了一个专门设计的视频压缩网络,将不同尺寸的视频内容压缩进一个名为“隐空间”(latent space)的特定维度中,转化为一系列“时空块”(temporal patch)。这一步骤极大地简化了视频处理的复杂性,为后续的高效处理奠定了基础。
随后,Sora 采用了先进的 Diffusion Transformer 技术对这些时空块进行去噪处理。这种去噪技术类似于图像和视频处理中的降噪技术,但更复杂、更精细,能够去除由压缩引入的噪声和失真,恢复出高质量的视频信息。
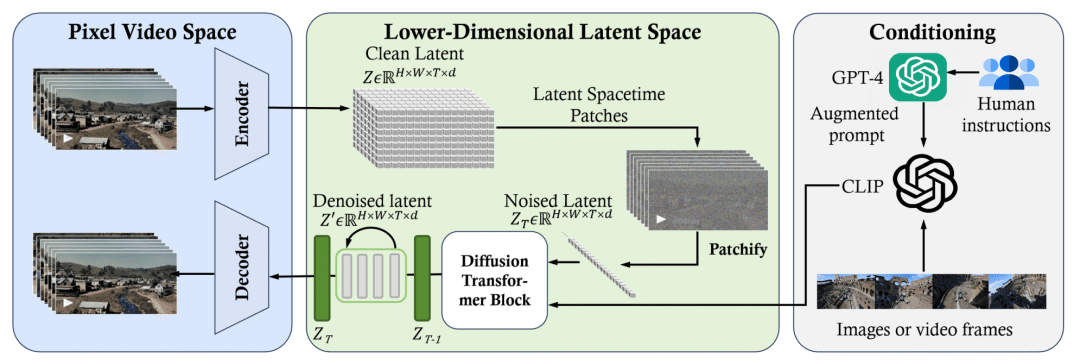
根据上面描述的技术原理,Open-Sora 将 Sora 可能使用的训练流程归纳为下图。
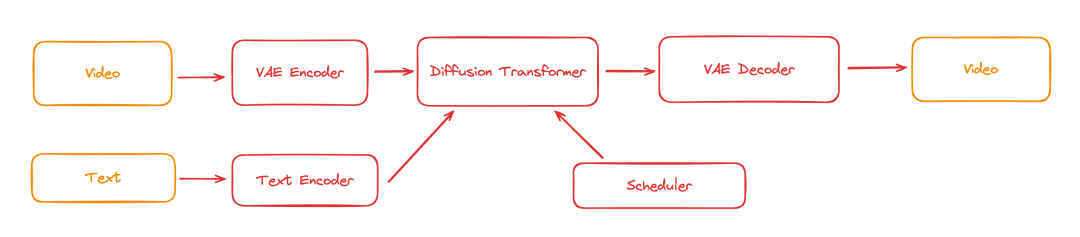
综上所述,Open-Sora 作为 Sora 技术的复现框架,用 Python 实现了将原视频转化成通用型大模型能处理的最小单元 patches 的模块(patches 类似文本的 token),然后在去噪步骤提供了 3 种常见的多模态模型结构。
目前 Open-Sora 提供的功能,如下:
-
完整的 Sora 复现架构:包含从数据处理到训练推理全流程。 -
动态分辨率:训练时可直接训练任意分辨率的视频,无需进行缩放。 -
多种模型结构:由于 Sora 实际模型结构未知,我们实现了 adaLN-zero、cross attention、in-context conditioning(token concat)等 3 种常见的多模态模型结构。 -
多种视频压缩方法:用户可自行选择使用原始视频、VQVAE(视频原生的模型)、SD-VAE(图像原生的模型)进行训练。 -
多种并行训练优化:支持结合 Colossal-AI 的 AI 大模型系统优化能力,及 Ulysses 和 FastSeq 的混合序列并行。
模型训练的确需要巨大的计算资源和时间成本,因此任何能够降低这些成本的优化都显得尤为重要。Open-Sora 的出现,以令人瞩目的 46% 成本节省,为我们展示了如何高效地进行类 Sora 视频生成模型的复现。而且,它还将模型训练的输入序列长度大幅扩展到近百万,这无疑进一步提升了模型的性能和处理能力。
性能优化
不同于 LLM 的大模型、大激活,Sora 类训练任务的特点是模型本体不大(如在 10B 以下),但是由于视频复杂性带来的序列长度特别长。
在此情况下,PyTorch 数据并行已无法运行,而传统的模型并行、零冗余数据并行带来的收益有限。因此,在支持 AMP(FP16/BF16)、Flash Attention、Gradient checkpointing、ZeRO-DP 等场景优化策略的基础上,Open-Sora 进一步引入两种不同的序列并行方法实现,可以 ZeRO 一起使用实现混合并行:
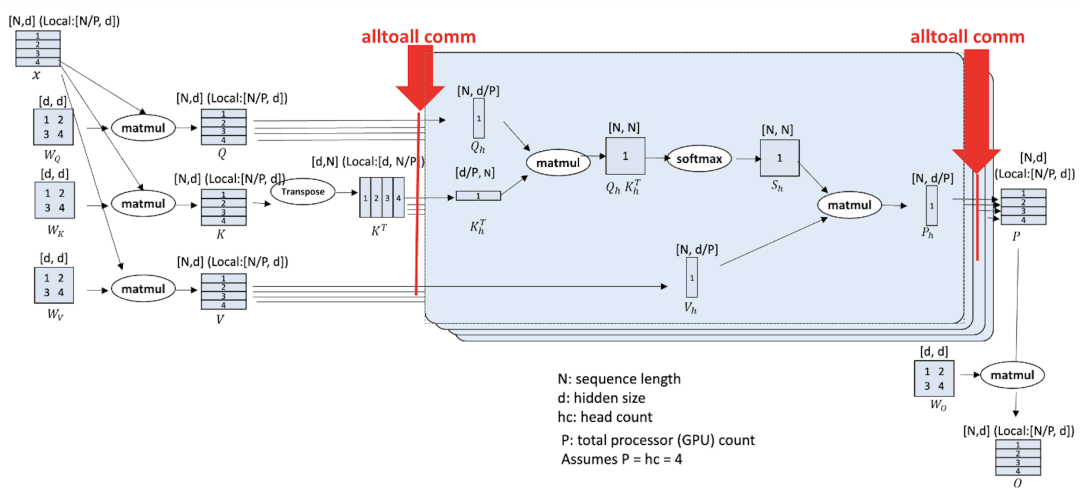
-
通用性较强的 Ulysses,对小规模或长序列表现可能更好。 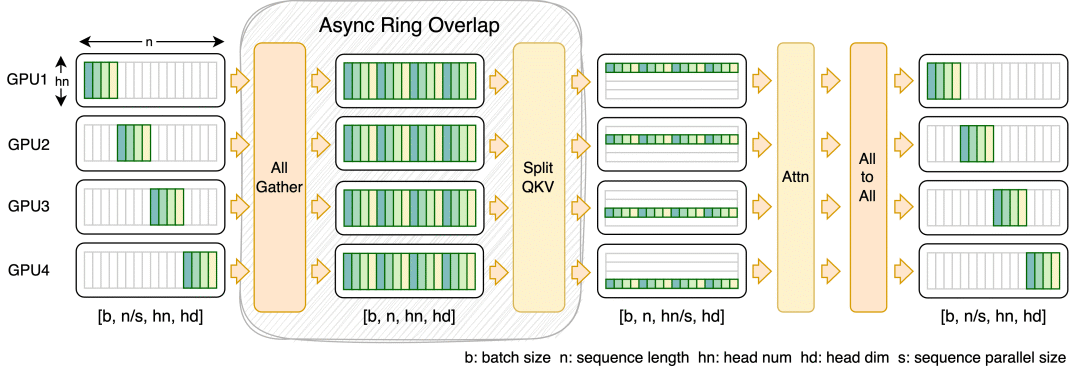
-
FastSeq 能将 qkv projection 的计算和 all-gather 通信重叠,只需多占用一点内存就可更进一步提升训练效率。
这两种序列并行方案,都可以轻松与 ZeRO2 共同使用来实现混合并行。
以在单台 H800 SXM 8*80GB GPU 上使用 DiT-XL/2 模型的性能测试为例。
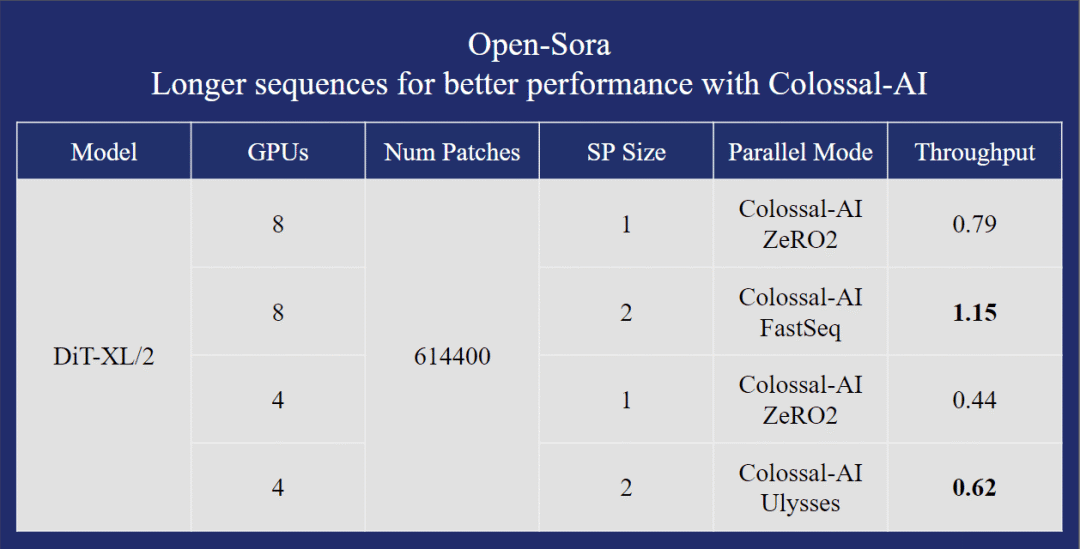
在 600K 的序列长度时,Open-Sora 的方案比基线方案有 40% 以上的性能提升和成本降低。
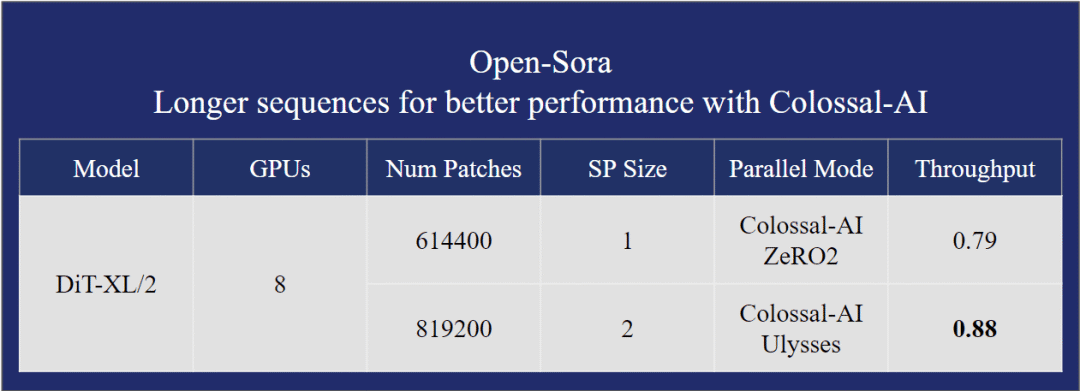
在保证更快训练速度的情况下,Open-Sora 还能训练 30% 更长的序列,达到 819K+。
最后
在视频内容迅速占据主流地位的今天,AI生成视频技术成为了众人瞩目的焦点,而Sora的惊艳亮相更是将这一领域推向了新的高潮。然而,今天我们所介绍的Open-Sora,尽管刚刚开源,尚未提供训练完成的类Sora模型,无法直接用于视频生成,但它的出现依然引发了极大的关注。
Open-Sora为视频生成领域提供了一套经过精心优化的低成本开发框架,旨在为用户提供方便易用、成本低廉且质量可靠的开源解决方案。尽管我们不能直接利用它生成视频,但Open-Sora的出现无疑为那些渴望探索Sora技术、有志于复现并赶超Sora的研究者和开发者们打开了一扇大门。
对于对Open-Sora感兴趣的朋友们,你们可以深入研究其源码(基于Python),或者参与到开源社区中,共同为复现Sora、推动视频生成技术的进步贡献力量。尽管篇幅有限,无法展开更多的技术细节,但相信随着社区的不断壮大和技术的持续迭代,Open-Sora将为视频生成领域带来更多的惊喜和突破。
GitHub 地址:https://github.com/hpcaitech/Open-Sora


